井生产的特征分类分析#
说明#
进行数模历史拟合时比较有效的方法是对同一类的井进行统一调整,或者通过对井的计算结果规律分析了解模型与实际油藏存在的差别然后进行调整;这些工作如果使用常规的后处理工具需要人工反复的查看曲线进行对比,效率很低效果还不好。这里采用SimRes和scikit-learn结合将数模结果进行自动特征分类分析。
自动对比分析需要在Python中安装SimRes的Python模块,详见 SimRes油藏数模后处理库 。
数模结果需要是兼容ECLIPSE软件的二进制格式或者RSM文本格式。
本例中对SPE9模型的26口井计算结果进行分析,选取含水率作为参数。采用KMeans、AffinityPropagation和SpectralClustering三种方法进行分类(三种方法均按照预期6类进行聚类分析)。
备注
可以将本例中的代码进行扩展,同时对多个参数进行井的分类,然后将参数的分类结果结合起来。
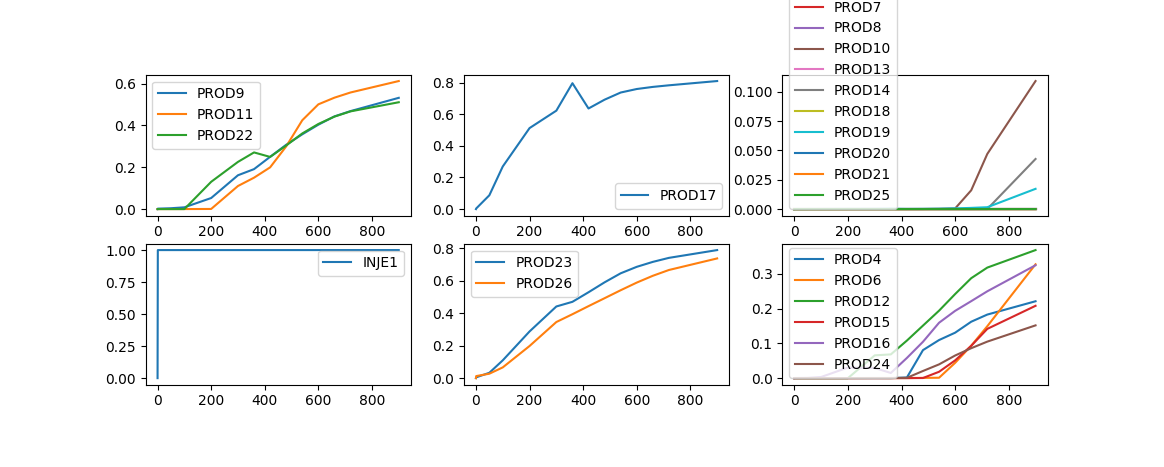
使用KMeans方法进行分类的结果#
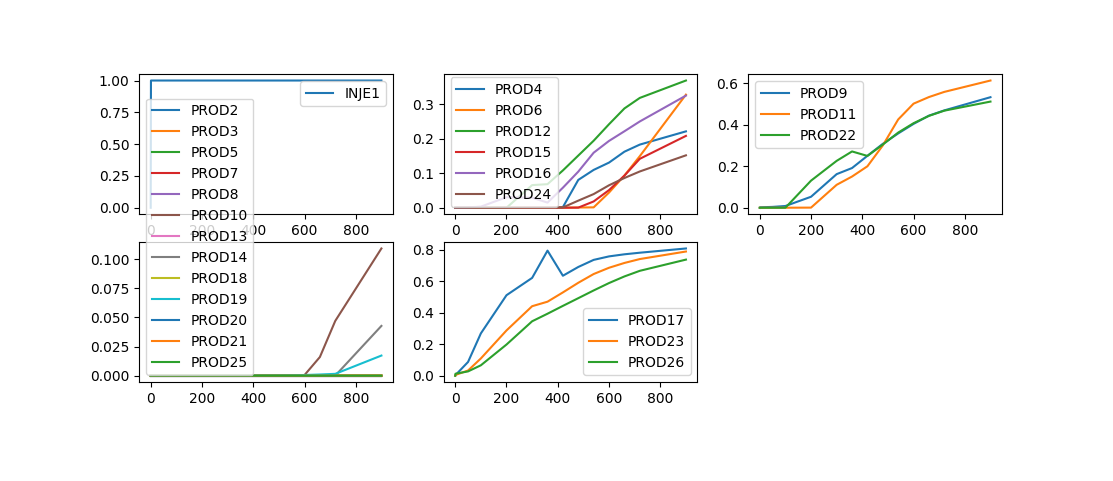
使用AffinityPropagation方法进行分类的结果#
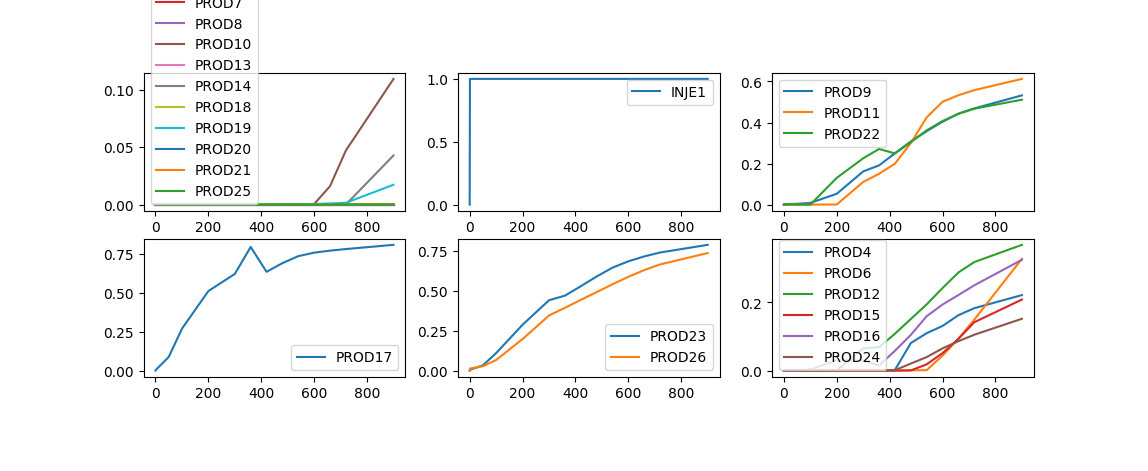
使用SpectralClustering方法进行分类的结果#
从结果可以看到KMeans、SpectralClustering两种方法对于生产有异常的PROD17井与其它井之间有较好的区分,而AffinityPropagation并没有太好的识别出来,而是将PROD17与其它几口井分成了一类。
示例文件请点击 下载 。
备注
本例中的SPE9模型计算结果是使用cflow模拟器计算,所以结果存在Data文件目录中的MRSRESULT子目录下
本例只是通过简单的示例展示了如何将数值模拟和有效的分析方法联系起来,更多的复杂方法可以请大家自己探索。